
Про шрифты с продолжением
ASCII (American Standard Code for Information Interchandge)
ISO 2022 (аналог ECMA-35, 1994 г.)
Так получилось, что публикации последних лет на шрифтовые темы в основном касались дизайна шрифтов и дизайна с использованием этих шрифтов, а вот техническую сторону вопроса практически никто не рассматривал. Давайте попробуем пройти этим путем от самого простого до максимально сложного этапов.
Что было до Unicode
Для полного понимания темы напомним, что было определено еще раньше:
- бит — это один двоичный разряд в двоичной системе счисления — 0 или 1;
- двоичный код — это упорядоченный набор битов, обычно фиксированной длины;
- байт как единица хранения цифровой информации — это набор битов фиксированной длины. И длина совсем необязательно должна равняться 8 битам, как это принято считать. Иногда байтом называют последовательность битов, которые составляют подполе машинного слова, используемое для кодирования одного текстового символа (правильнее называть это символом, а не байтом). На некоторых компьютерах возможна адресация слов разной длины — 6, 8, 9, 16 битов и т.д.;
- для вывода информации на экран или печатающее устройство используются алфавитные, числовые или специальные символы;
- каждый символ имеет определенную последовательность битов;
- кодовая таблица представляет собой матричную форму строк и столбцов, наглядно показывающую соответствие каждому символу его двоичного кода;
- Shift Code — это код, в котором значение битов зависит не только от собственной комбинации, но и от места в потоке данных.
Всё это до сих пор имеет смысл, хотя терминология несколько изменилась. Например, сегодня байт априори считается фиксированной длины — 8 бит, символы называются глифами, а кодовая таблица является просто способом графического представления кодировки. В былые времена позиции символов в кодировке определялись двойным номером «X / Y», где Х — номер колонки, а Y — номер строки. Сегодня достаточно дать его номер в десятичной или шестнадцатеричной форме.
Да что там, если быть точным, то первое кодирование информации придумали еще греки около 350 года до н.э. Они использовали его для дальней связи с помощью факелов. Для кодирования своей азбуки они применяли 32 комбинации из пяти зажженных или потушенных факелов.
А в конце XVIII века Клод Шапп создал первую телеграфную связь — между Парижем и Лиллем (225 км) с помощью оптического телеграфа (система башен с подвижными шестами). Его система сохраняла свое значение до введения электрического телеграфа в середине XIX века. Как мы знаем, именно для электрического телеграфа Самуэль Морзе в 1837 году изобрел свой «код Морзе», в котором используется переменное число длинных и коротких импульсов — точек и тире (чем не 0 и 1?). Именно код Морзе стал первой международно признанной системой кодирования.
Еще одно значимое событие — в 1874 году Эмиль Бодо адаптировал код Френсиса Бэкона для телеграфа. Код вводился с клавиатуры, состоящей из пяти клавиш, нажатие или ненажатие клавиши соответствовало передаче или непередаче одного бита в пятибитном коде. Максимальная скорость передачи — чуть больше 190 знаков в минуту (или 16 бит в секунду, или 4 бода).
Взяв за основу код Бодо, в 1901 году Дональд Мюррей переработал его, изменил порядок знаков и добавил некоторые дополнительные знаки. Это было связано с изобретением клавиатуры для телеграфного аппарата. Теперь порядок кодов был не связан с требованиями удобства оператора, и они были переупорядочены, чтобы минимизировать износ оборудования при переключении. Общие принципы — пятибитная кодировка и использование буквенного и цифрового регистров — остались неизменными. Модификация нового кода была принята в 1932 году как стандарт ITA2 или CCITT2 (табл. 1). В СССР была принята модификация CCITT2 с дополнительным регистром для кириллицы — МТК2.
В табл. 1 CR означает возврат каретки, SP — пробел, LF — перевод строки, LS (буквенный регистр) и FS (цифровой регистр) являются двумя кодами смены регистра. Например, при FS происходит следующая смена (табл. 2). Здесь сочетание *** предназначено для использования национальных символов (#, $, & в США; Ä, Ö, Ü в Германии, Швеции и Финляндии; Æ, Ø, Å в Дании и Норвегии), сочетание AB — для ответа, BEL — звонок.
Таблица 1
![]()
Таблица 2
![]()
С помощью LS мы возвращаемся к предыдущему регистру.
Не очень удобно, правда? Это всё оттого, что первоначально никто не собирался применять компьютеры для обработки текстов. В ту пору считалось, что они хороши только для обработки чисел. Никто ведь не пытается обрабатывать тексты на калькуляторе! Так раньше и компьютер ассоциировался только с числами.
FIELDATA
Во второй половине 50х годов прошлого столетия для армии США с целью организации связи был разработан семибитный код, известный как FIELDATA (табл. 3). Он не был совместим ни с чем и ни в чем. Символы в нем произвольным образом перемешаны с управляющими командами, причем сами команды явно избыточны: например, наряду с полным набором прописных и строчных букв присутствуют команды переключения Upper Case/Lower Case. Код включал не только кодировку, но и спецификации электрических параметров, разьемов и пр. Он был предназначен для аппаратного кодирования/декодирования и использовался, например, в компьютерах Univac и Unisys.
Таблица 3

MS расшифровывается как master space, UC/LC — смена кодов прописных и строчных букв, STOP, SPEC и IDLE обозначают «стоп», «специальное» и «неиспользуемый». В этой кодировке мы уже можем найти коды символов, которые несколько лет спустя будут применяться в ASCII. Код FIELDATA сохранился до нашего времени в старом ПО, написанном на Коболе (COBOL), для которого первоначально был выбран именно этот стандарт представления символов.
ASCII (American Standard Code for Information Interchandge)
К концу 1950х годов телекоммуникационная отрасль удвоила свои усилия по разработке стандартной кодировки. IBM и AT&T были среди крупных корпораций, образовавших ASA (Американскую ассоциацию стандартов) для создания новой кодировки. Таким образом, кодировка ASCII1963 — предварительная версия ASCII без какихлибо строчных знаков — появилась 17 июня 1963 года.
Код ASCII был обновлен в 1967 году. С тех пор он включает и строчные буквы. ASCII1967 показан в табл. 4.
Таблица 4
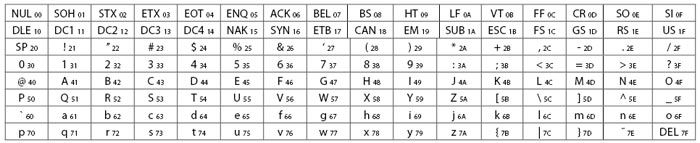
Первые 32 позиции в этой кодировке занимают управляющие коды:
- коды форматирования и управления: CR (Carriage Return — возврат каретки), LF (Line Feed — перевод строки), BS (Backspace — возврат на один символ; сегодня — возврат с удалением предыдущего символа), HT (Horizontal Tab — горизонтальная табуляция), VT (Vertical Tab — вертикальная табуляция), SP (Space — пробел), FF (Form Feed — прогон страницы);
- расширения: ESC (Escape), SO (Shift Out — измени цвет ленты — использовался для двухцветных лент; цвет менялся обычно на красный. В дальнейшем обозначал начало использования национальной кодировки), SI (Shift In — возврат от SO);
- контроль за сообщением: SOH (Start Of Heading — начало заголовка), STX (Start of Text — начало текста), ETX (End of Text — конец текста), EOT (End of Transmission — конец передачи), ETB (End of Text Block — конец текстового блока), АСК (Acknowledgement — подтверждение), NAK (Negative Acknowledgment — нет подтверждения), SYN (Synchronization — код синхронизации), NUL (Null — пустой), DLE (Data Link Escape — следующие символы имеют специальный смысл);
- символы управления устройствами: DC1. . . DC4;
- функции обработки ошибок: CAN (Cancel — отмена), SUB (Substitute — подставить), Del (Delete — удалить последний символ), BEL (Bell — звонок).
Здесь уже появились символы, которые не использовались для управления:
- обратный слэш «\», применяемый в DOS в качестве разделителя (путь к каталогу) и в TEX как сигнальный символ, были введены в кодировках в сентябре 1961 года и впоследствии приняты в ASCII1963;
- апостроф «‘» представляет собой вертикальный штрих, а не поднятую запятую, как это многим представляется;
- то же самое относится к «двойным» (неориентированным) кавычкам «,,», которые служат для обрамления цитат в американском стиле;
- гравис «`» — знак обратного ударения;
- вертикальная черта «|» была введена для обозначения оператора «ИЛИ» в языке PL/I.
Собственно стандарт ASCII определяет только семибитный код, то есть с его помощью можно закодировать 128 символов. Этого достаточно, чтобы представить 52 латинские буквы (строчные и прописные), цифры, знаки препинания, арифметические действия, различные скобки и наиболее употребительные спецсимволы вроде знака доллара или процента. Кроме того, с целью придания стандарту большей универсальности коды с номерами 131 (код 0 не используется) были отведены под команды принимающему устройству, среди которых есть как никому не нужные теперь «звонок» или «запрос», так и широко употребляемые «конец строки» и «перевод каретки». Код 32 означает «пробел».
Чтобы хранить также коды национальных символов каждой страны (в нашем случае — символов кириллицы), требуется добавить еще 1 бит, что увеличит количество уникальных комбинаций из нулей и единиц вдвое, то есть в нашем распоряжении дополнительно появится 128 свободных кодов (со 128го по 255й), в соответствие которым можно поставить символы русского алфавита.
Таким образом, отведя под хранение информации о коде каждого символа 8 бит, мы получим N = 28 = = 256 уникальных двоичных кодов — этого достаточно, чтобы закодировать все символы, которые можно ввести с клавиатуры. Для национальных расширений разработчики оставили вторую половину восьмибитной таблицы — коды со 128го до 256го, где в оригинале содержались буквы с диакритическими знаками, некоторые спецсимволы и символы псевдографики, позволяющие, например, оформить текст в виде таблицы или нарисовать символ интеграла.
EBCDIC
Хотя IBM принимала участие в разработке ASCII1963, в 1964 году она выпустила новую линию компьютеров — IBM System/360, для которых вплоть до начала 80х годов использовался другой код — EBCDIC, весьма громоздко устроенный и ведущий свое начало от перфокарт (табл. 5). С ним подавляющему большинству пользователей столкнуться вряд ли случится.
Таблица 5
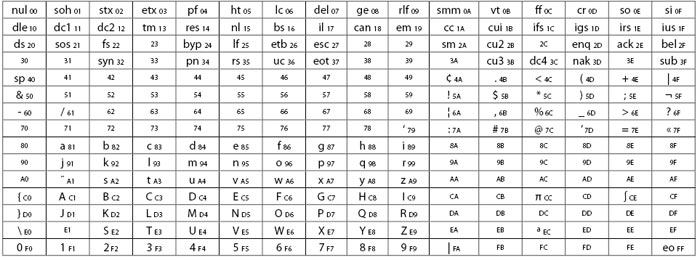
Что за странная кодировка? — спросите вы. Чтобы понять ее, надо совершить небольшой исторический экскурс.
В 1801 году парижский ткач ЖозефМари Жаккард придумал прообраз перфокарт для работы на автоматических ткацких станках (машина Жаккарда).
Семьдесят девять лет спустя по другую сторону Атлантики, в Соединенных Штатах, крайне неудачно была проведена перепись населения. Неудачность ее состояла в том, что она заняла 7 лет (!), и большая часть этого времени была потрачена на обработку данных. Столкнувшись с такой проблемой, Бюро переписи населения организовало конкурс, чтобы найти изобретения, которые помогли бы решить ее. Конкурс выиграл Герман Холлерит, представивший прообраз компьютера, работающего с перфокартами, — электрическую табулирующую систему (Hollerith Electric Tabulating System).

Стандартная перфокарта
Холлерит организовал фирму по производству табуляционных машин TMC (Tabulating Machine Company), и стал продавать их железнодорожным управлениям и правительственным учреждениям (партия табуляторов была закуплена и Российской империей). Этому предприятию сопутствовал успех. С годами оно претерпело ряд изменений — слияний и переименований. С 1924 года фирма Холлерита стала называться IBM (International Business Machines).
Но какое отношение Холлерит имеет к EBCDIC? Посмотрите на рисунок. На нем показана стандартная перфокарта. Обратите внимание, что перфокарта имеет двенадцать строк, две из которых перфорируются, но не обозначены (их называют Х и Y), а оставшиеся десять несут цифровые обозначения от 0 до 9. Холлерит изобрел систему, с помощью которой можно закодировать буквы и цифры, не используя более двух отверстий на колонку. Система так и называется — код Холлерита (табл. 6).
Таблица 6
Отметка |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
На оси X |
A |
B |
C |
D |
E |
F |
G |
H |
I |
|
На оси Y |
J |
K |
L |
M |
N |
O |
P |
Q |
R |
|
На нулевой |
S |
T |
U |
V |
W |
X |
Y |
Z |
||
Цифры |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
Иными словами, чтобы получить А, пробиваются отверстия в колонке на строке X и на строке 1; чтобы получить S — в строке 2 и в строке 0 и т.д. На приведенной в примере перфокарте это можно легко проверить — закодированные слова продублированы на карте вверху обычным печатным способом.
Таким образом, код Холлерита был использован для кодирования перфокарт, то есть как код EBCDIC.
Несмотря на очевидные недостатки, IBM распространила этот код повсюду — было создано 57 национальных версий EBCDIC.
ISO 2022 (аналог ECMA-35, 1994 г.)
В начале 1970х годов использовалось сразу несколько кодировок, которые действительно были весьма различны, и рано или поздно приходилось переходить из одной кодировки в другую в середине многоязычного документа. Как же можно было отметить изменение кодировки?
Именно в это время появился стандарт ISO 2022 (1973 г.), последняя ревизия которого относится к 1994 году. Это не кодирование в полном смысле слова, а определенное количество управляющих последовательностей, дающих возможность применять до четырех кодировок в рамках одного и того же набора данных.
Согласно стандарту ISO 2022, были введены понятия «управляющий символ» и «графический символ», например CR, LF и ESC — это управляющие символы. Соответственно всё пространство из 28 =
= 256 символов разбивается на четыре части (табл. 7):
- C0 (Control Left) — 0x000x1F;
- GL (Graphic Left) — 0x200x7F;
- C1 (Control Rigth) — 0x800x9F;
- GR (Graphic Right) — 0xA00xFF.
Таким образом, под отображаемые символы (Graphic) отводится только 2562х32 = 192 позиции, 96 GL и 96 GR (иногда 94, без первой и последней позиций).
Одной из функций управляющих символов является переключение наборов символов в GR и GL. То есть всё происходит внутри 8битного пространства. Для этого применяются управляющие ESCпоследовательности, «старший» ESC — CSI и коды SI (Shift In) и SO (Shift Out). Так, КОИ7 сделан в точном соответствии со стандартом ISO2022 путем переключения GL кодами SI и SO.
Таблица 7
C0 |
GL |
C1 |
GR |
|||||||||||||
x0 |
x1 |
x2 |
x3 |
x4 |
x5 |
x6 |
x7 |
x8 |
x9 |
xA |
xB |
xC |
xD |
xE |
xF |
|
x0 |
SP |
|||||||||||||||
x1 |
||||||||||||||||
x2 |
||||||||||||||||
x3 |
||||||||||||||||
x4 |
||||||||||||||||
x5 |
||||||||||||||||
x6 |
||||||||||||||||
x7 |
||||||||||||||||
x8 |
||||||||||||||||
x9 |
||||||||||||||||
xA |
||||||||||||||||
xB |
ESC |
|||||||||||||||
xC |
||||||||||||||||
xD |
||||||||||||||||
xE |
||||||||||||||||
xF |
DEL |
|||||||||||||||
Например, большинство принтеров используют для переключения кодовых наборов именно различные ESCпоследовательности. И при выводе на печать постоянно происходит переключение наборов символов с помощью управляющих кодов. Точно такая же картина с терминалами. Например, терминалы DEC VTXXX или Wyse имеют множество национальных наборов символов, вшитых в микрокод. Даже код переключения кодовых наборов у консоли Linux (echo ne “\033(K”) — это тоже разновидность последовательности ISO2022.
Каждой половине, GR и GL, может быть назначен определенный набор символов (Charset). Существуют четыре набора графических символов — G0/G1/G2/G3, каждый из которых может быть подключен на место GL или GR. Как правило, в 8битных системах для GL назначается обычный ASCII, а GR переключают.
Вдобавок каждый из Charset’ов G0/G1/G2/G3 можно сменить с помощью «назначателей» (designators). Получается довольно сложная и громоздкая система.
Международные стандарты серии ISO8859x (например, ISO88591: Latin1) сконструированы с учетом требований ISO 2022. «Назначатели» для них также стандартизованы. Например, для кодировки ISO 88595 «назначателями» будут: G1 — ESC x2/Dx x4/Cx; G2 — ESC x2/Ex x4/Cx; G3 — ESC x2/Fx x4/Cx (ECMA35: G1 — ESC 2/13 4/12; G2 — ESC 2/14 4/12; G3 — ESC 2/15 4/12).
Одним из недостатков ISO 2022 является запрет на использование позиций «старших» управляющих символов C1 (0x800x9F) для кодирования букв. Например, кодировка CP866 не соответствует стандарту ISO2022, поскольку код буквы «Ы» (0x9B) совпадает со старшим ESC (CSI).
Кодировки на основе ISO 2022 практически в чистом виде, то есть вместе с ESCсимволами и «назначателями», широко применяются для кодирования японских символов (система JIS) и имеют зарегистрированные MIME charset’ы: ISO2022JP (RFC1468) и ISO2022JP1 (RFC2237).
ISO 8859
Семейство ASCIIсовместимых кодовых страниц, разработанное совместными усилиями ISO и IEC. По состоянию на 2006 год оно включало 15 кодовых страниц.
Поскольку кодировки ISO 8859 разрабатывались как средства для обмена информацией, а не как средства обеспечения высококачественной типографики, в них отсутствуют такие символы, как парные кавычки, тире различной длины, лигатуры и т.п. (хотя там все же присутствуют такие символы, как неразрывный пробел и символ мягкого переноса). Зато довольно много места (область 0x800x9F) зарезервировано под «верхние управляющие символы», предназначенные для управления терминалами.
Поскольку различные страницы ISO 8859 разрабатывались совместно, они обладают некоторой взаимной совместимостью. Например, все семь символов расширенной латиницы, используемые в немецком языке, стоят на одинаковых позициях во всех кодовых страницах, включающих эти символы. Страницы Latin1—Latin4 обладают еще большей степенью совместимости: каждый символ, представленный в любой из этих страниц, стоит в них на одинаковых позициях.
Кодировки серии ISO 8859 применяются главным образом на юниксоподобных системах, а также для кодирования вебстраниц (поскольку большинство вебсерверов использует UNIX).
В системах Microsoft Windows применяются кодировки Windows, некоторые из них совместимы с ISO 8859, но включают больше графических символов за счет использования области 0x800x9F.
Части ISO 8859
ISO 88591 (Latin1)
Расширенная латиница, включающая символы большинства западноевропейских языков (английский, датский, ирландский, исландский, испанский, итальянский, немецкий, норвежский, португальский, ретороманский, фарерский, шведский, шотландский (гэльский) и частично голландский, финский, французский), а также некоторых восточноевропейских (албанский) и африканских языков (африкаанс, суахили). В Latin1 отсутствуют знак евро и заглавная буква Ÿ. Эта кодовая страница считается кодировкой по умолчанию для HTMLдокументов (в XHTML используется UTF8) и сообщений электронной почты. Также этой кодовой странице соответствуют первые 256 символов Юникода.
ISO 88592 (Latin2)
Расширенная латиница, включающая символы центральноевропейских и восточноевропейских языков (боснийский, венгерский, польский, словацкий, словенский, хорватский, чешский). В Latin2, как и в Latin1, отсутствует знак евро.
ISO 88593 (Latin3)
Расширенная латиница, включающая символы южноевропейских языков (мальтийский, турецкий) и эсперанто.
ISO 88594 (Latin4)
Расширенная латиница, включающая символы североевропейских языков (гренландский, эстонский, латвийский, литовский и саамские языки).
ISO 88595 (Latin/Cyrillic)
Кириллица, включающая символы славянских языков (белорусский, болгарский, македонский, русский, сербский и частично украинский).
ISO 88596 (Latin/Arabic)
Символы, используемые в арабском языке. Символы других языков с письмом на основе арабского не поддерживаются. Для корректного отображения текста в кодировке ISO 88596 требуется поддержка двунаправленного письма и контекстнозависимых форм символов.
ISO 88597 (Latin/Greek)
Символы современного греческого языка. Может использоваться также для записи древнегреческих текстов в монотонической орфографии.
ISO 88598 (Latin/Hebrew)
Символы современного иврита. Применяется в двух вариантах: с логическим порядком следования символов (требует поддержки двунаправленного письма) и с визуальным порядком следования символов.
ISO 88599 (Latin5)
Вариант Latin1, в котором редко используемые символы исландского языка заменены на турецкие. Применяется для турецкого и курдского языков.
ISO 885910 (Latin6)
Вариант Latin4, более удобный для скандинавских языков.
ISO 885911 (Latin/Thai)
Символы тайского языка.
ISO 885912 (Latin/Devanagari)
Символы письма деванагари. В 1997 году работа над ISO 885912 была официально прекращена, и эта кодировка так и не была принята как стандарт.
ISO 885913 (Latin7)
Вариант Latin4, более удобный для балтийских языков.
ISO 885914 (Latin8)
Расширенная латиница, включающая символы кельтских языков, таких как шотландский (гэльский) и бретонский.
ISO 885915 (Latin9)
Вариант Latin1, в котором редко используемые символы заменены на необходимые для полной поддержки финского, французского и эстонского языков. Кроме того, в Latin9 добавлен знак евро.
ISO 885916 (Latin10)
Расширенная латиница, включающая символы южноевропейских и восточноевропейских (албанский, венгерский, итальянский, польский, румынский, словенский, хорватский), а также некоторых западноевропейских языков (ирландский в новой орфографии, немецкий, финский, французский). Как и в Latin9, в Latin10 был добавлен знак евро.
Продолжение следует