
Про шрифты с продолжением. Часть 2
Продолжение. Начало см. в КомпьАрт №3 2010.
ISO 8859-1 (Latin-1) и ISO 8859-15 (Latin-9)
Кодовый набор ISO 8859-1 (Latin-1) базировался на мультинациональном шрифтовом наборе, использованном компанией DEC в популярном терминале VT220. Он был разработан в рамках ECMA (European Computer Manufecturers Association) и опубликован в марте 1985 года (ECMA-94).
В Юникоде первые 256 кодовых позиций совпадают с ISO 8859-1.
В Microsoft Windows для западноевропейских языков применяется кодировка Windows-1252, которая отличается от ISO 8859-1 тем, что позиции 128-159 здесь заняты разными полезными типографскими символами. Большинство браузеров не различают ISO 8859-1 и Windows-1252 — фактически и в том, и в другом случае они отображают текст как Windows-1252.
Путаница между этими двумя кодировками привела к тому, что многие программы, генерирующие файлы HTML, ошибочно обозначали символы соответствующими кодами из Windows-1252 вместо кодов Юникода (исходя из того, что номер символа в ISO 8859-1 равен его номеру в Юникоде): например, тире (—) обозначалось — вместо правильного —, многоточие — … вместо правильного … и т.д.; из-за распространенности этого явления современные браузеры продолжают показывать, например, — как тире, хотя на самом деле — — это управляющий символ end of guarded area, применение которого в HTML бессмысленно (табл. 8).
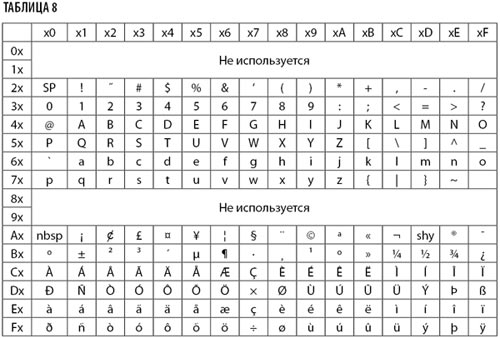
Или для GR (учитывая, что C0 и GL идентичны ASCII, а C1 не используется) — см. табл. 9.

Некоторые символы необходимо расшифровать:
- NBSP (non-breaking space) — это неразрывный пробел;
- «¡» и «¿» — испаноязычные восклицательный и вопросительный знаки, которые используются в начале предложения.
- «¢», «£» и «¥» — символы валюты: знак цента, британский фунт и японская иена;
- «¤» — так называемый универсальный знак валюты. Когда-то итальянцы предложили этот символ в качестве замены для знака доллара в некоторых локализациях и «политически правильной» версии ASCII;
- «ª» и «º» применяются в испанском, итальянском и португальском языках в качестве цифровой приставки гендерной составляющей (например, 1ª — первая; 2º — второй);
- SHY — мягкий перенос;
- «°» — знак градуса, который, как ни крути, сильно отличается от нуля и буквы «О» в позиции степени. Мы пишем «Nº», но «36,6 °С»;
- срединная точка (midpoint) «·» — используется для формирования каталанский лигатуры «l·l»;
- немецкий эсцет (eszett) «ß» — лигатура из fz (в готическом шрифте) или fs (в антикве), первым элементом которой является так называемое длинное S. Ныне применяется только в немецком языке, но до XIX века более или менее регулярно использовалась практически во всех средневековых европейских языках с письменностями на латинской основе, особенно в курсиве. В немецких словарях при упорядочении по алфавиту знак ß обычно приравнивается к ss. Следует помнить, что замена символом ß двух букв ss не всегда правомерна, так как применение символа ß подразумевает удлинение предшествующей гласной, тогда как ss — ее укорочение. Не следует также путать латинскую лигатуру ß и греческую строчную букву «бета» (β);
- «ÿ» (Y с диерезисом) — используется в валлийском и старом французском языках.
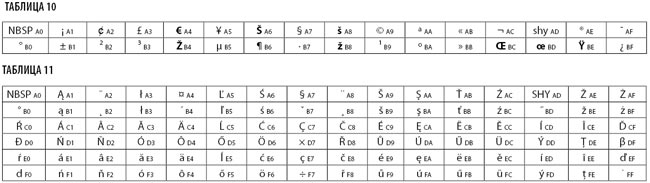
В марте 1999 года, когда появилась настоятельная необходимость в добавлении знака евро, ISO воспользовался этим, чтобы исправить стратегические ошибки: были добавлены лигатуры «Œ» и «œ», а также буква «Ÿ», необходимые для французов. Еще были добавлены буквы «Z», «z», «Š», «š», которые применяются в большинстве стран Центральной Европы. Знак евро (€) занял место символа универсальной денежной валюты.
Новый стандарт называется ISO 8859-15 (или Latin-9). Он отличается от ISO 8859-1 только по восьми позициям (выделены полужирным в табл. 10).
ISO 8859-2 (Latin-2) и ISO 8859-16 (Latin-10)
После стандарта ISO 8859-1, который также известен как ISO Latin-1, вышло еще три кодировки для латиницы: по одной для стран Восточной (ISO 8859-2), Южной (ISO 8859-3) и Северной (ISO 8859-4) Европы.
Таким образом, ISO 8859-2 (или Latin-2) включает символы, необходимые для некоторых языков Центральной и Восточной Европы: боснийского, хорватского, чешского, венгерского, польского, румынского, словацкого, словенского и сербского. Он также содержит символы, необходимые для немецкого и французского языков (табл. 11).
В 2001 году, уже после выхода ISO 8859-15, ISO сделал то же самое для ISO 8859-2: ISO 8859-16 (или Latin-10) — последней кодировки из стандарта 8859. Она охватывает языки Центральной Европы (польский, чешский, словенский, словацкий, венгерский, албанский, румынский), а также французский (с лигатурой «œ»), немецкий и итальянский. Кроме того, сюда включены румынские знаки «s» и «t» (табл. 12).

ISO 8859-3 (Latin-3) и ISO 8859-9 (Latin-5) (iso-ir-109, ISO_8859-3, latin3, l3, csISOLatin3)
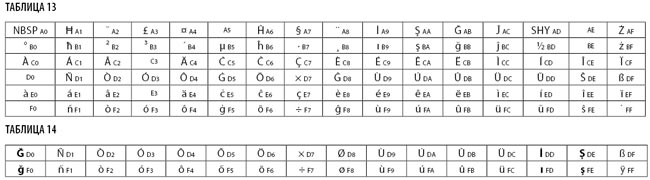
ISO 8859-3 (Latin-3) посвящена «южным» языкам плюс эсперанто. В нее входят символы из ISO 8859-1 и ISO 8859-2, а также несколько пустых блоков (табл. 13).
В 1989 году турки, недовольные ISO 8859-3, добились принятия ISO 8859-9 (Latin-5), которая отличается от ISO 8859-1 только шестью знаками (выделены полужирным) табл. 14.
ISO 8859-4 (Latin-4), ISO 8859-10 (Latin-6), ISO 8859-13 (Latin-7)
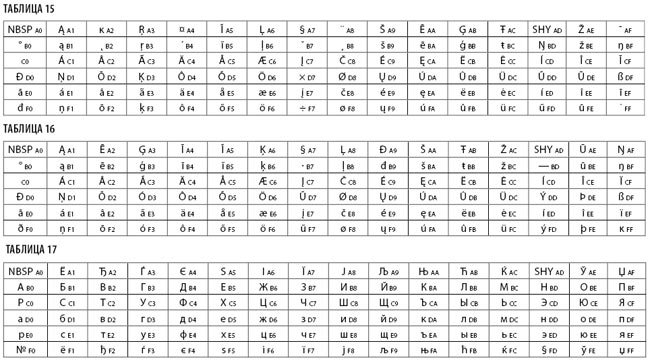
Стандарт ISO 8859-4 (Latin-4) посвящен языкам Севера. Но поскольку датский, шведский, норвежский, финский и исландский уже охвачены ISO 8859-1, то под «языками Севера» здесь понимаются страны Балтии: Литва, Латвия, Эстония и Гренландия. Сюда же входит и саамский (табл. 15).
В 1992 году для языков Севера была создана новая кодировка — ISO 8859-10 (Latin-6) — табл. 16.
Комментарий:
- у изолированной «ß» появилась пара — гренландская «к», которая в верхнем регистре идентична обычной «K»;
- знак «Ð» встречается дважды: в позиции 0xA9 как хорватская «dje» (в нижнем регистре «d») и в позиции 0xD0 как исландская «eth» (в нижнем регистре «ð»).
В 1998 году вышел стандарт ISO 8859-13 (Latin-7) для балтийских языков, скомбинированный с польскими знаками.
ISO 8859-5, 6, 7, 8, 11
В качестве предыстории к ISO 8859-5 вспомним, что в середине 70-х годов появилась кодировка КОИ, в которой русские буквы во второй половине таблицы ставились на такие места, чтобы при вычитании 128 из кода получалась соответствующая по звучанию (но не всегда по написанию) английская буква, причем в противоположном регистре, чтобы отличить английский текст от русского. Например, слова «Русский Текст» превратились бы в «rUSSKIJ tEKST». Факт остается фактом: долгое время КОИ-8 существовал в виде общесоюзного стандарта (ГОСТ 19768-74) и даже чуть было не был утвержден в качестве международного (ISO-IR-111 или ECMA-Cyrillic). Даже сейчас KOI-8r (всего кодировок с общим названием КОИ существует не менее семи) как был, так и остается самым распространенным стандартом для электронной почты. А в конце 80-х годов он был возведен в ранг интернет-стандарта под названием RFC-1489. Тут, конечно, сыграло свою роль то, что он и был к тому времени стандартом де-факто (подкрепленным авторитетом ГОСТа) для UNIX-систем, которые доминировали в Сети.
Надо признать, что КОИ-8 довольно-таки неудобен. Попытки придумать чтото более удобоваримое были. Одна из них даже сменила КОИ-8 в качестве общесоюзного стандарта (ГОСТ 19768-87). Этот ГОСТ, кстати, действует и поныне. Путаницу усугубили специалисты из ISO, которые включили новый порядок кириллических букв в международный стандарт под названием ISO 8859-5 (табл. 17). Упомянутый ГОСТ и стандарт ISO 8859-5 оказались настолько «нестандартными», что их решительно никто не использует. Госстандат сейчас спокойно приветствует посетителей на своем сайте в кодировке Win1251. Альтернативные варианты этого стандарта можно встретить под названиями: csISOLatinCyrillic, iso-ir-144, ISO 8859-5:1988, iso-8859_5-1999.

Стандарт ISO 8859-6 (Arabic) использует символы арабского языка. Символы других языков с письмом на основе арабского не поддерживаются. Для корректного отображения текста в кодировке ISO 8859-6 требуется поддержка двунаправленного письма и контекстно-зависимых форм символов. Отсутствуют «wasla» и вертикальная «fatha». Альтернативные инкарнации данного стандарта: csISOLatinArabic, iso-ir-127, ISO 8859-6:1987, iso-8859_6-1999, ECMA-114.
ISO 8859-7 (Greek) содержит символы современного греческого языка. Может использоваться также для записи древнегреческих текстов в монотонической орфографии. Альтернативы: csISOLatinGreek, iso-ir-126, ISO 8859-7:1987, iso-8859_7-1987, ECMA-118, ELOT_928.
ISO 8859-8 (Hebrew) включает символы современного иврита (csISOLatinHebrew, iso-ir-138, iso-8859_8-1999). Применяется в двух вариантах: с логическим порядком следования символов (требует поддержки двунаправленного письма) и с визуальным порядком следования символов. Идиш отсутствует.
ISO 8859-11 (Thai) содержит символы тайского языка (windows-874, windows-874-2000). Этот стандарт — прямой наследник TIS 620 от 1986 года. Хорошо проработан и на самом деле охватывает не только тайский, но и упрощенную версию кхмерского языка.
ISO 8859-14 (Latin-8)
Охватывает кельтские знаки: ирландский гэльский (гаэльский), шотландский и валлийский. Довольно полный набор знаков. Из недостатков можно отметить лишь отсутствие лигатуры «c’h».
Дальний Восток
Из всех азиатско-дальневосточных стран лучше всего дело с кодировками обстоит в Японии. В 1976 году, через три года после выпуска ISO 2022, японцы подготовили первую GR-кодировку, то есть 94 дополнительных знака к ASCII, — JIS C 6220 (в 1987 году была переименована в JIS X 0201-1976). Кодировка JIS C 6220, основанная на JISCII (1969 г.), содержит только катакану и несколько идеографических знаков препинания (точка, запятая, кавычки, повышенная точка).
1 января 1978 года, после девяти лет упорной работы, первая истинно японская кодировка — JIS C 6226-1978, известная сегодня как old JIS, — официально вступила в силу. Она содержит 6694 знака: латиницу, греческий и кириллический алфавиты, кана и 6349 иероглифов кандзи. С тех пор стандарт был пересмотрен три раза. Последняя версия — JIS X 0208-1997 от января 1997 года.
В 1990 году была выпущена вторая японская кодировка — JIS X 0212-1990. Она дополняет первую 5801 иероглифом и 266 другими символами. Третья кодировка — JIS X 0213-2000 — появилась в январе 2000 года. Она дополнена еще двумя уровнями кандзи в дополнение к двум JIS X 0208-1997: третий уровень содержит 1249 иероглифов, четвертый — 2436.
Китай тоже не отстает от Японии: в 1981 году он выпустил первую китайскую кодировку — GB 2312-80. Эта кодировка, в которой содержится 7445 символов, совместима со стандартом ISO 2022.
Со временем было принято множество дополнений. К 1992 году количество символов составило 8443. После Культурной революции КНР приняла упрощенную систему написания иероглифов, поэтому существуют кодировки как для традиционной, так и для упрощенной формы письменности.
Тайвань также не остался в стороне. В 1984 году вышел стандарт, называемый в простонародье «Большая пятерка» — над его созданием трудились сотрудники пяти крупнейших корпораций Тайваня. В этом стандарте содержится 13 494 символа, 13 053 из которых иероглифы, расположенные на двух уровнях. Наконец, в 1992 году увидела свет кодировка CNS 11643-1992, которая побила все рекорды по числу символов: всего их 48 711, в том числе 48 027 иероглифов, организованных в семи частях примерно по 6-8 тыс. символов.
Что касается других стран, говорящих на китайском языке, в основном Сингапура и Гонконга, то они тоже все чаще используют «Большую пятерку».
В Южной Корее в 1992 году была принята кодировка KS X 1001-1992, в которой содержится 4888 иероглифов, 2350 фонематических символов хангыль (hangul) и 986 других символов, включая латиницу, греческий, кириллицу и японскую кана, имитирующие этой частью JIS X 0208-1997.
Первая северокорейская кодировка KPS 9566-97 от 1997 года содержала 4653 иероглифа, 2679 символов хангыль и 927 других символов. Как водится, кодировки Южной и Северной Кореи совершенно несовместимы. Кроме того, позиции от 0x0448 до 0x044D выполняют важную государственную функцию: они содержат имена «великих вождей» Ким Ир Сена и его сына Ким Чен Ира.
Microsoft’s code pages
Поскольку первоначально кодирование предназначалось для ОС DOS, то здесь мы видим набор графических символов, используемых для рисования интерфейсов пользователя через простую композицию из прямых, углов, крестов и т.д. Есть даже решетки пикселов, которые моделируют различные оттенки серого.
В США наиболее часто применяются кодовые страницы 437 (United States) и 850 (Multilingual). В обоих случаях это 128 знаков ASCII (вся верхняя половина таблицы) плюс дополнения. На рис. 2 показано, как выглядит 437-я страница, обозначенная как MS-DOS Latin US.
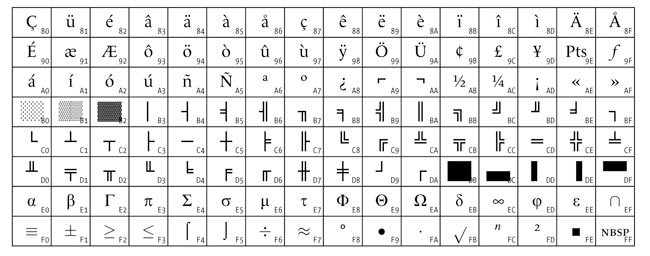
Рис. 2. 437-я страница MS-DOS
Конечно же, 437-й страницей кодировка не исчерпывается. Другие кодовые страницы MS-DOS: арабские 708-710, 720 и 864; монотонический греческий — 737 и 869; 775 (страны Балтии); 852 (страны Центральной Европы); 855 и 866 (кириллица; причем 866-я только для русского языка); 857 (турецкий); 860 (португальский); 861 (исландский); 862 (иврит без кратких гласных); 863 (канадский французский как компиляция 437 и 850); 865 (северные страны); 874 (тайский); 932 (японский); 936 (упрощенный китайский); 949 (Корея); 950 (традиционный китайский).
Что касается России, то из всех возникших в конце 80-х годов кириллических кодировок наибольшее распространение получила так называемая альтернативная кодировка. Своим названием она обязана тому, что была выдвинута как альтернатива никому не нужному ГОСТу. Сейчас она больше известна как CP866 (Code Page 866) или кириллическая кодировка MS DOS. Пожалуй, это самая продуманная из всех кодировок. Прежде всего на своих местах остались символы псевдографики и многие другие спецсимволы из второй половины ASCII, то есть оформленный с их помощью английский текст абсолютно не меняется независимо от текущей кодовой страницы. Некоторое неудобство состоит в том, что русские символы располагаются в таблице с разрывом: строчная буква «п» имеет номер 175, а «р» и далее начинаются с номера 224, буквы «Ё» и «ё» замещают довольно часто употребляемые символы 240 (знак тождества) и 241 (плюс/минус), что иногда приводит к разным некрасивостям. Но это недостатки простительные. Кроме «альтернативной», в начальный период распространения персоналок в странах СЭВа действовали болгарская MIC (которая до сих пор используется в болгарской Linux), какая-то «польская» (ныне нигде не упоминаемая), «украинская», почти все разновидности КОИ и CP855, в которой символы кириллицы расположены совершенно иначе, чем в CP866.
В эпоху Windows необходимость в графических символах отпала, и Microsoft решила принять за основу ISO 8859, но избежать ее главного недостатка — символы 0x80-0x9F не были управляющими в реализации Microsoft.
Таким образом, кодовая страница 1252 Windows Latin 1, также известная как ANSI, является кодировкой ISO 8859-1 с добавлением двух строк (табл. 18).
Кодовая страница 1250 Windows Latin 2 расширяет и изменяет ISO 8859-2. Изменения претерпели позиции 0x80-0xBF (табл. 19).
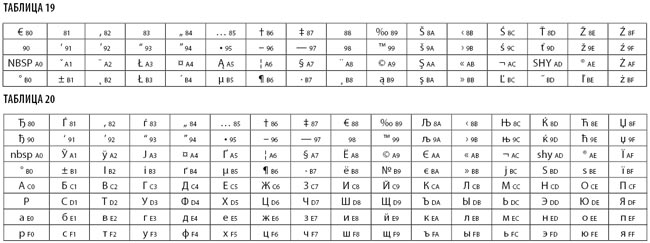
Упомянем и кодовую страницу 1251 Windows Cyrillic. Она выгодно отличается от других 8-битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, используемых в русской типографике для обычного текста (отсутствует только значок ударения), и содержит все символы для близких к русскому языку языков: украинского, белорусского, сербского и болгарского (табл. 20).
Данная кодировка имеет два недостатка:
- строчная буква «я» имеет код 0xFF (255 в десятичной системе). Она является виновницей ряда неожиданных проблем в программах без поддержки чистого 8-го бита, а также (гораздо более частый случай) использующих этот код как служебный (в CP437 он обозначает неразрывный пробел, в Windows-1252 — «ÿ», оба варианта практически не применяются; число же –1, в дополнительном коде длиной 8 бит представляемое числом 255, часто используется в программировании как специальное значение, например индикатор конца файла EOF часто представляется значением –1);
- отсутствуют символы псевдографики, имеющиеся в CP866 и KOI8 (хотя для самих Windows, для которых она предназначена, в них не было нужды; это сделало несовместимость двух применявшихся в них кодировок более заметной).
Apple’s encodings
Компания Macintosh с самого начала использовала собственные кодировки. Необычность кодировок Macintosh состоит в том, что как кодовые страницы MS DOS они включают математические символы. Поскольку большинство шрифтов не содержит эти символы, в Mac OS была предусмотрена специальная процедура замещения недостающих символов из системных шрифтов. Другая особенность кодировок Macintosh — они включают лигатуры «fi» и «fl», а также знаменитый значок надкусанного яблока, который Apple использует в качестве своего логотипа.
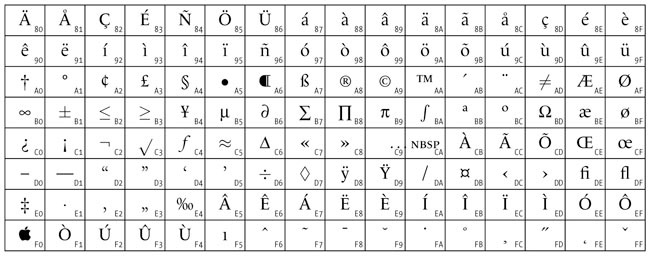
Рис. 3. Кодировка Standard Roman
Кодировка, показанная на рис. 3, применяется на макинтошах и называется Standard Roman.
Кодировка CP10007 (Macintosh Cyrillic; Mac OS Cyrillic character set; x-mac-cyrillic) — табл. 21.
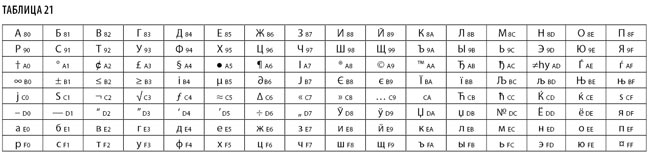
Разумеется, существуют и другие кодировки: Icelandic, Turkish, Central European, Arabic (арабский, персидский, урду), Chinese Traditional, Greek (монотонический), Hebrew, Japanese, Korean, Devanagari, Gujarati, Gurmukhi и Thai.
Продолжение следует