
Про шрифты с продолжением. Часть 3
Символы, знаки и байты: введение в Юникод
Другие общие свойства (Other general properties)
Как читать записи стандарта Unicode
Символы, знаки и байты: введение в Юникод
Юникод (англ. Unicode) — стандарт кодирования, позволяющий представить знаки практически всех письменных языков. Он был предложен в 1991 году некоммерческой организацией Unicode Consortium, Unicode, Inc. Применение этого стандарта позволяет закодировать очень большое число символов из разных письменностей: в документах Unicode могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, при этом становятся ненужными кодовые страницы.
Стандарт состоит из двух основных разделов: универсальный набор символов (universal character set, UCS) и семейство кодировок (Unicode transformation format, UTF). Универсальный набор символов задает однозначное соответствие символов кодам — элементам кодового пространства, представляющим неотрицательные целые числа. Семейство кодировок определяет машинное представление последовательности кодов UCS.
Коды в стандарте Юникод разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунк-туации и технические символы. Часть кодов зарезервирована для использования в будущем. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F (рис. 4 и 5), от U+2DE0 до U+2DFF (рис. 6), от U+A640 до U+A69F (рис. 7).

Рис. 4. Базовый русский, расширенная кириллица: украинский, македонский, сербский, старославянский, башкирский, татарский и др.
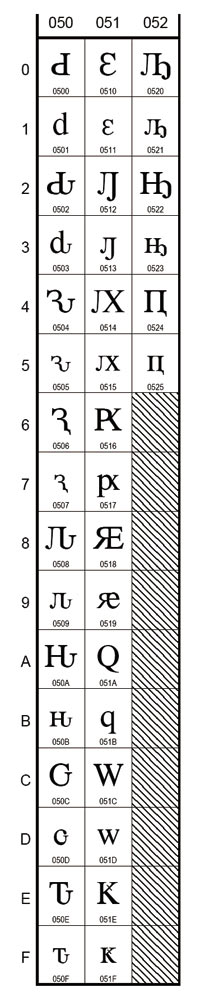
Рис. 5. Расширенная кириллица: современный абхазский, чувашский, алеутский, мордовский, коми, чукотский, ханты и др.

Рис. 6. Старославянские модифицирующие знаки

Рис. 7. Старославянский и староабхазский
Первая версия Unicode представляла собой кодировку с фиксированным размером символа в 16 бит, то есть общее число кодов было 216 (65 536). Отсюда происходит практика обозначения символов четырьмя шестнадцатеричными цифрами (например, U+0410). При этом в Юникоде планировалось кодировать не все существующие символы, а только те, которые необходимы в повседневном обиходе. Редко применяемые символы должны были размещаться в «области символов для частного использования» (Private Use Area), которая первоначально занимала коды от U+D800 до U+F8FF. Чтобы применять Юникод и в качестве промежуточного звена при преобразовании разных кодировок друг в друга, в него включили все символы, представленные во всех наиболее известных кодировках.
В дальнейшем, однако, было принято решение кодировать все символы и в связи с этим значительно расширить кодовую область. Одновременно с этим коды символов стали рассматриваться не как 16-битные значения, а как абстрактные числа, которые в компьютере могут представляться множеством разных способов.
Поскольку в ряде компьютерных систем (например, Windows NT) фиксированные 16-битные символы уже использовались в качестве кодировки по умолчанию, было решено все наиболее важные знаки кодировать только в пределах первых 65 536 позиций (так называемая basic multilingual plane, BMP). Остальное пространство применяется для «дополнительных символов» (англ. supplementary characters): систем письма вымерших языков или очень редко используемых китайских иероглифов, математических и музыкальных символов.
Для совместимости со старыми 16-битными системами была изобретена система UTF-16, где первые 65 536 позиций, за исключением позиций из интервала от U+D800 до U+DFFF, отображаются непосредственно как 16-битные числа, а остальные представляются в виде «суррогатных пар» (первый элемент пары из области U+D800…U+DBFF, второй элемент пары из области U+DC00…U+DFFF). Для суррогатных пар была использована часть кодового пространства (2048 позиций), ранее отведенного для Private Use Area.
Поскольку в UTF-16 можно отобразить только 220+216–2048 (1 112 064) символов, то это число и было выбрано в качестве окончательной величины кодового пространства Юникода.
Хотя кодовая область Юникода была расширена за пределы 216 уже в версии 2.0, первые символы в «верхней» области были размещены только в версии 3.1.
По мере изменения и пополнения таблицы символов системы Юникода и выхода новых версий этой системы (эта работа ведется постоянно, поскольку изначально система Юникод включала только Plane 0 — двухбайтные коды) выходят и новые документы ISO. Система Юникод существует в общей сложности в следующих версиях:
- 1.1 (соответствует стандарту ISO/IEC 10646—1:1993), стандарт 1991-1995 го-дов;
- 2.0, 2.1 (тот же стандарт ISO/IEC 10646—1:1993 плюс дополнения: Amendments с 1-го по 7-е и Technical Corrigenda 1 и 2), стандарт 1996 года;
- 3.0 (стандарт ISO/IEC 10646—1:2000), стандарт 2000 года;
- 3.2, стандарт 2002 года;
- 4.0, стандарт 2003 года;
- 4.01, стандарт 2004 года;
- 4.1, стандарт 2005 года;
- 5.0, стандарт 2006 года;
- 5.1, стандарт 2008 года;
- 5.2, стандарт 2009 года.
Хотя формы записи UTF-8 и UTF-32 позволяют кодировать до 231 (2 147 483 648) кодовых позиций, было принято решение использовать лишь 1 112 064 для совместимости с UTF-16. Впрочем, даже и этого более чем достаточно — сегодня (в версии 5.1) применяется немногим более 100 тыс. кодовых позиций.
Кодовое пространство разбито на 17 плоскостей (подмножеств) по 216 (65 536) символов. Нулевая плоскость называется базовой, в ней расположены символы наиболее употребительных письменностей. Первая плоскость используется в основном для исторических письменностей, вторая — для редко применяемых иероглифов, третья зарезервирована для архаичных китайских иероглифов ККЯ. Плоскости 15 и 16 выделены для частного употребления (табл. 22).
Таблица 22
Плоскость |
Диапазон |
Описание |
Аббревиатура |
0 |
0000—FFFF |
Базовая многоязыковая плоскость |
Basic Multilingual Plane, BMP |
1 |
10000—1FFFF |
Дополнительная многоязыковая плоскость |
Supplementary Multilingual Plane, SMP |
2 |
20000—2FFFF |
Дополнительная иероглифическая плоскость |
Supplementary Ideographic Plane, SIP |
3 |
30000—3FFFF |
Третичная иероглифическая плоскость |
Tertiary Ideographic Plane, TIP |
4-13 |
40000—DFFFF |
Не используются |
|
14 |
E0000—EFFFF |
Дополнительная |
Supplementary Special-purpose Plane, SSP |
15 |
F0000—FFFFF |
Применяется как дополнительная область A для частного использования |
Supplementary Private Use Area-A, SPUA-A |
16 |
100000—10FFFF |
Применяется как дополнительная область B для частного использования |
Supplementary Private Use Area-B, SPUA-B |
Для обозначения символов Unicode используется запись вида «U+xxxx» (для кодов 0…FFFF), или «U+xxxxx» (для кодов 10000…FFFFF), или «U+xxxxxx» (для кодов 100000…10FFFF), где xxx — шестнадцатеричные цифры. Например, символ «я» (U+044F) имеет код 044F16 = 110310.
Универсальная система кодирования (Юникод) представляет собой набор графических символов и способ их кодирования для компьютерной обработки текстовых данных.
Графические символы — это символы, имеющие видимое изображение. Графическим символам противопоставляются управляющие символы и символы форматирования.
Графические символы включают следующие группы:
- буквы, содержащиеся хотя бы в одном из обслуживаемых алфавитов;
- цифры;
- знаки пунктуации;
- специальные знаки (математические, технические, идеограммы и пр.);
- разделители.
Юникод — это система для линейного представления текста. Символы, имеющие дополнительные над или подстрочные элементы, могут быть представлены в виде построенной по определенным правилам последовательности кодов (составной вариант, composite character) или в виде единого символа (монолитный вариант, precomposed character).
Графические символы в Юникоде подразделяются на протяженные и непротяженные (бесширинные). Непротяженные символы при отображении не занимают места в строке. К ним относятся, в частности, знаки ударения и прочие диакритические знаки. Как протяженные, так и непротяженные символы имеют собственные коды. Протяженные символы иначе называются базовыми (англ. base characters), а непротяженные — модифицирующими (англ. combining characters), причем последние не могут встречаться самостоятельно. Например, символ «á» может быть представлен как последовательность базового символа «a» (U+0061) и модифицирующего символа «'» (U+0301) или как монолитный символ «á» (U+00C1).
Особый тип модифицирующих символов — селекторы варианта начертания (англ. variation selectors). Они действуют только на те символы, для которых такие варианты определены. В версии 5.0 варианты начертания определены для ряда математических символов, для символов традиционного монгольского алфавита и для символов монгольского квадратного письма.
Поскольку одни и те же символы можно представить различными кодами, что иногда затрудняет обработку, существуют процессы нормализации, предназначенные для приведения текста к определенному стандартному виду.
В стандарте Юникода определены четыре формы нормализации текста:
- форма нормализации D (NFD) — каноническая декомпозиция. В процессе приведения текста в эту форму все составные символы рекурсивно заменяются на несколько составных в соответствии с таблицами декомпозиции;
- форма нормализации C (NFC) — каноническая декомпозиция с последующей канонической композицией. Сначала текст приводится к форме D, после чего выполняется каноническая композиция — текст обрабатывается от начала к концу в соответствии со следующими правилами:
- символ S является начальным, если он имеет нулевой класс модификации в базе символов Юникода,
- в любой последовательности символов, стартующей с начального символа S, символ C блокируется от S, если и только если между S и C есть какойлибо символ B, который или является начальным, или имеет одинаковый либо больший класс модификации, чем C. Это правило распространяется только на строки, прошедшие каноническую декомпозицию,
- первичным композитом считается символ, у которого есть каноническая декомпозиция в базе символов Юникода (или каноническая декомпозиция для хангыля и он не входит в список исключений);
- символ X может быть первично совмещен с символом Y, если и только если существует первичный композит Z, канонически эквивалентный последовательности <X, Y>,
- если очередной символ C не блокируется последним встреченным начальным базовым символом L и может быть успешно первично совмещен с ним, то L заменяется на композит L-C, а C удаляется;
- форма нормализации KD (NFKD) — совместимая декомпозиция. При приведении в эту форму все составные символы заменяются, используя как канонические карты декомпозиции Юникода, так и совместимые карты декомпозиции, после чего результат ставится в каноническом порядке;
- форма нормализации KC (NFKC) — совместимая декомпозиция с последующей канонической композицией.
Под терминами «композиция» и «декомпозиция» понимают соответственно соединение или разложение символов на составные части.
Стандарт Юникод поддерживает письменности языков с направлением написания как слева направо (left-to-right, LTR), так и справа налево (right-to-left, RTL) — например арабское и еврейское письмо. В обоих случаях символы хранятся в «естественном» порядке; их отображение с учетом нужного направления письма обеспечивается приложением.
Кроме того, Юникод поддерживает комбинированные тексты, сочетающие фрагменты с разным направлением письма. Данная возможность называется двунаправленностью (bidirectional text, BiDi). Некоторые упрощенные обработчики текста (например, в сотовых телефонах) могут поддерживать Юникод, но не иметь поддержки двунаправленности. Все символы Юникода поделены на несколько категорий: пишущиеся слева направо, пишущиеся справа налево и пишущиеся в любом направлении. Символы последней категории (в основном это знаки пунк-туации) при отображении принимают направление окружающего их текста.
Юникод включает практически все современные письменности, в том числе арабскую, армянскую, бенгальскую, бирманскую, глаголицу, греческую, грузинскую, деванагари, еврейскую, кириллицу, китайскую (китайские иероглифы активно используются в японском языке, а также, довольно редко, в корейском), коптскую, кхмерскую, латинскую, тамильскую, корейскую (хангыль), чероки, эфиопскую, японскую (которая, кроме китайских иероглифов, включает еще и слоговую азбуку) и др.
С академическими целями добавлены многие исторические письменности, в том числе руны, древнегреческая, египетские иероглифы, клинопись, письменность майя, этрусский алфавит.
В Юникоде представлен широкий набор математических и музыкальных символов, а также пиктограмм.
Однако в Юникод принципиально не включаются логотипы компаний и продуктов, хотя они и встречаются в шрифтах (например, логотип Apple в кодировке MacRoman (0xF0) или логотип Windows в шрифте Wingdings (0xFF)). В юникодовских шрифтах логотипы должны размещаться только в Private Use Area.
Консорциум Юникода работает в тесной связи с рабочей группой ISO/IEC/JTC1/SC2/WG2, которая занимается разработкой международного стандарта 10646 (ISO/IEC 10646). Между стандартом Юникода и ISO/IEC 10646 установлена синхронизация, хотя каждый стандарт использует свою терминологию и систему документации.
Сотрудничество консорциума Юникода с Международной организацией по стандартизации (англ. International Organization for Standardization, ISO) началось в 1991 году. В 1993-м ISO выпустила стандарт DIS 10646.1. Для синхронизации с ним консорциум утвердил стандарт Юникода версии 1.1, в который были внесены дополнительные символы из DIS 10646.1. В результате значения закодированных символов в Unicode 1.1 и DIS 10646.1 полностью совпали.
В дальнейшем сотрудничество двух организаций продолжилось. В 2000 году стандарт Unicode 3.0 был синхронизирован с ISO/IEC 10646-1:2000. Предстоящая третья версия, ISO/IEC 10646, будет синхронизирована с Unicode 4.0. Возможно, эти спецификации даже будут опубликованы как единый стандарт.
Аналогично форматам UTF-16 и UTF-32 в стандарте Юникода, стандарт ISO/IEC 10646 также имеет две основные формы кодирования символов: UCS-2 (2 байта на символ, аналогично UTF-16) и UCS-4 (4 байта на символ, аналогично UTF-32). UCS — значит универсальный многооктетный (многобайтовый) кодированный набор символов (universal multiple-octet coded character set). UCS-2 можно считать подмножеством UTF-16 (UTF-16 без суррогатных пар), а UCS-4 является синонимом для UTF-32.
Юникод имеет несколько форм представления (Unicode transformation format, UTF): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). Была разработана также форма представления UTF-7 для передачи по семибитным каналам, но из-за несовмес-тимости с ASCII она не получила распространения и не включена в стандарт. 1 апреля 2005 года были предложены две шуточные формы представления: UTF-9 и UTF-18 (RFC 4042).
В Microsoft Windows NT и основанных на ней системах Windows 2000 и Windows XP в основном используется форма UTF-16LE. В UNIX-подобных операционных системах GNU/Linux, BSD и Mac OS X принята форма UTF-8 для файлов и UTF-32 или UTF-8 для обработки символов в оперативной памяти.
UTF-8
Формат UTF-8 был изобретен 2 сентября 1992 года Кеном Томпсоном и Робом Пайком и реализован в Plan 9. Сейчас стандарт UTF-8 официально закреплен в документах RFC 3629 и ISO/IEC 10646 Annex D.
UTF-8 (Unicode Transformation Format — формат преобразования Юникода) — в настоящее время распространенная кодировка, реализующая представление Юникода, совместимое с 8-битным кодированием текста. Нашла широкое применение в операционных системах и вебпространстве.
Текст, состоящий только из символов Юникода с номером меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. И наоборот, в тексте UTF-8 любой байт со значением меньше 128 изображает символ ASCII с тем же кодом. Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байт (реально только до 4 байт, поскольку использование кодов больше 221 не планируется), в которых первый байт всегда имеет вид 11xxxxxx, а остальные — 10xxxxxx.
Проще говоря, в формате UTF-8 символы латинского алфавита, знаки препинания и управляющие символы ASCII записываются кодами US-ASCII, а все остальные символы кодируются при помощи нескольких октетов со старшим битом 1. Это приводит к двум эффектам.
Даже если программа не распознает Юникод, то латинские буквы, арабские цифры и знаки препинания будут отображаться правильно.
В случае если латинские буквы и простейшие знаки препинания (включая пробел) занимают существенный объем текста, UTF-8 дает выигрыш по объему по сравнению с UTF-16.
На первый взгляд может показаться, что UTF-16 удобнее, так как в ней большинство символов кодируется ровно двумя байтами. Однако это сводится на нет необходимостью поддержки суррогатных пар, о которых часто забывают при использовании UTF-16, реализуя лишь поддержку символов UCS-2.
Символы UTF-8 получаются из Unicode следующим образом (табл. 23).
Таблица 23
Unicode |
UTF-8 |
Представленные символы |
0x00000000 — 0x0000007F |
0xxxxxxx |
ASCII, в том числе английский алфавит, простейшие знаки |
0x00000080 — 0x000007FF |
110xxxxx 10xxxxxx |
Кириллица, расширенная латиница, арабский, армянский, |
0x00000800 — 0x0000FFFF |
1110xxxx 10xxxxxx 10xxxxxx |
Все другие современные формы письменности, в том числе |
0x00010000 — 0x001FFFFF |
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
Музыкальные символы, редкие китайские иероглифы, |
Также теоретически возможны, но не включены в стандарты символы, указанные в табл. 24.
Таблица 24
Unicode |
UTF-8 |
0x00200000 — 0x03FFFFFF |
111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
0x04000000 — 0x7FFFFFFF |
1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
Символы, закодированные в UTF-8, могут быть длиной до 6 байт, однако стандарт Unicode не определяет символов выше 0x10ffff, поэтому символы Unicode могут иметь максимальный размер в 4 байт в UTF-8.
В тексте UTF-8 принципиально не может быть байтов со значениями 254 (0xFE) и 255 (0xFF). Поскольку в Юникоде не определены символы с кодами выше 221, то в UTF-8 также оказываются неиспользуемыми значения байтов от 248 до 253 (0xF8—0xFD). Если запрещены искусственно удлиненные (за счет добавления ведущих нулей) последовательности UTF-8, то не применяются также байтовые значения 192 и 193 (0xC0 и 0xC1).
Многие программы Windows (включая «Блокнот») добавляют байты 0xEF, 0xBB, 0xBF в начале любого документа, сохраняемого как UTF-8. Это метка порядка байтов Юникода (Byte Order Mark, BOM), ее также часто называют сигнатурой (соответственно UTF-8 и UTF-8 with Signature). Чтобы при сохранении избавиться от добавления сигнатуры, используйте, например, Notepad++ или более простой Notepad2.
Порядок байтов
В потоке данных UTF-16 старший байт может записываться либо перед младшим (UTF-16 big-endian), либо после младшего (UTF-16 little-endian). Аналогично существует два варианта четырехбайтной кодировки — UTF-32BE и UTF-32LE.
Для определения формата представления Юникода в текстовом файле используется прием, согласно которому в начале текста записывается символ U+FEFF (неразрывный пробел с нулевой шириной), также именуемый меткой порядка байтов (англ. byte order mark, BOM). Этот способ позволяет различать UTF-16LE и UTF-16BE, поскольку символа U+FFFE не существует. Также он иногда применяется для обозначения формата UTF-8, хотя к этому формату и неприменимо понятие порядка байтов. Файлы, следующие этому соглашению, начинаются с таких последовательностей байтов:
UTF-8: EF BB BF;
UTF-16BE: FE FF;
UTF-16LE: FF FE;
UTF-32BE: 00 00 FE FF;
UTF-32LE: FF FE 00 00.
Файлы в кодировках UTF-16 и UTF-32, не содержащие BOM, должны иметь порядок байтов big-endian.
К сожалению, этот способ не позволяет надежно различать UTF-16LE и UTF-32LE, поскольку символ U+0000 допускается Юникодом (хотя реальные тексты редко начинаются с него).
Реализации
Большинство современных операционных систем в той или иной мере обес-печивают поддержку Юникода.
В операционных системах семейства Windows NT для внутреннего представления имен файлов и других системных строк используется двухбайтовая кодировка UTF-16LE. Системные вызовы, принимающие строковые параметры, существуют в однобайтном и двухбайтном вариантах.
Современные операционные системы Windows XP и Windows Server 2003, как и предшествующие им Windows NT 4 и Windows 2000, поставляются с системными библиотеками, включающими функции обоих видов: юникодовые и предназначенные для работы со строками в текущей кодовой странице системы, условно называемой ANSI-страницей. При этом для вызова юникодовых функций применяется суффикс W (от слова wide — широкий, например lstrlenW()), а для вызова ANSI-функций — буква A (например, lstrlenA()). В результате на ОС семейства Windows NT запускаются и программы, способные использовать Юникод, и более старые программы, не способные одновременно работать с символами разных языков. Большинство ANSI-функций реализованы как оболочки над соответствующими юникодовыми функциями. Использовать при этом можно только поддерживаемые этими программами символы.
В Windows CE, начиная с самых первых версий, за исключением малого числа случаев, применялся только UTF-16.
В 2001 году корпорация Microsoft выпустила специальное дополнение к своим старым операционным системам Windows 95, Windows 98 и Windows Me. Оно называется уровнем Юникода (англ. Microsoft Layer for Unicode, MSLU) и обеспечивает поддержку Юникода на указанных старых платформах. Это дополнение включает динамическую библиотеку unicows.dll (всего 240 Кбайт), содержащую юникодовые версии (те, что с буквой W на конце) всех основных функций Windows API. В результате на старых операционных системах Windows стало возможно запускать как старые, так и новые программы, рассчитанные на использование Юникода.
UNIX-подобные операционные системы, в том числе GNU/Linux, BSD и Mac OS X, используют для представления Юникода кодировку UTF-8. Большинство программ могут работать с UTF-8, как с традиционными однобайтными кодировками, не обращая внимания на то, что символ представляется как несколько последовательных байтов. Для работы с отдельными символами строки обычно перекодируются в UCS-4, так что каждому символу соответствует машинное слово.
Одной из первых успешных коммерческих реализаций Юникода стала среда программирования Java. В ней принципиально отказались от 8-битного представления символов в пользу 16-битного. Сейчас большинство языков программирования поддерживает спецификацию Юникода, хотя их представление может различаться в зависимости от реализации.
Методы ввода
Поскольку ни одна раскладка клавиатуры не позволяет вводить все символы Юникода одновременно, от операционных систем и прикладных программ требуется поддержка альтернативных методов ввода произвольных символов Юникода.
Начиная с Windows 2000 служебная программа «Таблица символов» (charmap.exe) показывает все символы в ОС и позволяет копировать их в буфер обмена. Похожая таблица есть, например, в Microsoft Word.
Иногда можно набрать шестнадцатеричный код, нажать Alt+X — и код будет заменен на соответствующий символ, например, в WordPad, Word и адресной строке браузера. В редакторах Alt+X выполняет и обратное преобразование.
Для ввода в десятеричном виде можно с нажатой клавишей Alt набрать код на цифровой клавиатуре, в шестнадцатеричном виде — выставить (по умолчанию отсутствующее) строковое значение реестра HKEY_Current_User\Control Panel\Input Method\EnableHexNumpad равным 1, перезагрузиться, а затем, удерживая нажатой клавишу Alt и нажав «+» справа, набрать код. В разных местах Windows комбинации с Alt рабо-тают по-разному, например в блокноте Alt-937 даст «й» (в CP866 это символ с кодом 169=937 mod 256), Alt-0937 — «©» (169 в Latin-1), а Alt-Plus-3a9 — «Ω» из Юникода (3a916=937). В WordPad и Word во всех случах будет «Ω».
В Mac OS 8.5 и более поздних версиях поддерживается метод ввода, называемый Unicode Hex Input. При нажатой клавише Option требуется набрать четырехзначный шестнадцатеричный код требуемого символа. Этот метод позволяет вводить символы с кодами, большими U+FFFF, используя пары суррогатов; такие пары операционной системой будут автоматически заменены на одиночные символы. Этот метод ввода перед использованием нужно активировать в соответствующем разделе системных настроек, а затем выбрать как текущий метод ввода в меню клавиатуры.
Начиная с Mac OS X 10.2 существует также приложение Character Palette, позволяющее выбирать символы из таблицы, в которой можно выделять символы определенного блока или символы, поддерживаемые конкретным шрифтом.
В GNOME (GNU/Linux) также есть утилита «Таблица символов», позволяющая отображать символы определенного блока или системы письма и предоставляющая возможность поиска по названию или описанию символа. Когда код нужного символа известен, его можно ввести в соответствии со стандартом ISO 14755: при нажатых клавишах Ctrl и Shift ввести шестнадцатеричный код (начиная с некоторой версии GTK+ ввод кода нужно предварить нажатием клавиши «U»). Вводимый шестнадцатеричный код может иметь до 32 бит в длину, позволяя вводить любые символы Юникода без использования суррогатных пар.
Все приложения X Window, включая GNOME и KDE, поддерживают ввод при помощи клавиши Compose. Для клавиатур, на которых нет отдельной клавиши Compose, для этой цели можно назначить любую клавишу — например Caps Lock.
Консоль GNU/Linux также допускает ввод символа Юникода по его коду — для этого десятичный код символа нужно ввести цифрами расширенного блока клавиатуры при нажатой клавише Alt. Можно вводить символы и по их шестнадцатеричному коду: для этого нужно нажать клавишу AltGr. Поддерживается также ввод в соответствии с ISO 14755. Для того чтобы перечисленные способы могли работать, нужно включить юникодный режим консоли вызовом unicode_start(1) и выбрать подходящий шрифт вызовом setfont(8).
Проблемы Юникода
Как любая изобретенная человеком система, Юникод не лишен недостатков (хотя в основном они связаны с возможностями обработчиков текста, а не непосредственно с принципом кодирования).
Некоторые системы письма все еще не представлены должным образом в Юникоде. Изображение «длинных» надстрочных символов, простирающихся над несколькими буквами, как, например, в церковнославянском языке, пока не реализовано.
Тексты на китайском, корейском и японском языках имеют традиционное написание сверху вниз, начиная с правого верхнего угла. Переключение горизонтального и вертикального написания для этих языков не предусмотрено в Юникоде — это должно осуществляться средствами языков разметки или внутренними механизмами текстовых процессоров.
Первоначальная версия Юникода предполагала наличие большого количества готовых символов, в последующем было отдано предпочтение сочетанию букв с диакритическими модифицирующими знаками (combining diacritics). Например, русские буквы Ё (U+0401) и Й (U+0419) существуют в виде монолитных символов, хотя могут быть представлены и набором базового символа с последующим диакритическим знаком, то есть в составной форме (decomposed): «Е»+ «¨» (U+0415 U+0308), «И»+ «ˇ» (U+0418 U+0306). В то же время множество символов из языков с алфавитами на основе кириллицы не имеют монолитных форм.
Юникод предусматривает возможность разных начертаний одного и того же символа в зависимости от языка. Так, китайские иероглифы могут иметь разные начертания в китайском, японском (кандзи) и корейском (ханчча), но при этом в Юникоде обозначаться одним и тем же символом (так называемая CJK-унификация), хотя упрощенные и полные иероглифы все же имеют разные коды. Часто возникают накладки, когда, например, японский текст выглядит «по-китайски». Аналогично русский и сербский языки используют разное начертание курсивных букв «п» и «т» (в сербском они выглядят как «и» и «ш» с горизонтальной чертой сверху). Поэтому нужно следить, чтобы текст всегда был правильно помечен как относящийся к тому или иному языку.
Даже перевод из строчных букв в заглавные зависит от языка. Например, в турецком существуют буквы İi и Iı — таким образом, турецкие правила конвертации регистра конфликтуют с английскими, которые предписывают «i» переводить в «I».
Файлы с текстом в Юникоде занимают больше места в памяти, так как один символ кодируется не одним байтом, как в различных национальных кодировках, а последовательностью байтов (исключение составляет UTF-8 для языков, алфавит которых укладывается в ASCII; наличие в тексте символов двух и более языков, алфавит которых не укладывается в ASCII). Файл шрифта, необходимый для отображения всех символов таблицы Юникод, занимает сравнительно много места в памяти и требует больших вычислительных ресурсов. С увеличением мощности компьютерных систем и удешевлением памяти и дискового пространства эта проблема становится всё менее существенной, однако она остается актуальной для портативных устройств, например для мобильного телефона.
Хотя поддержка Юникода реализована в наиболее распространенных операционных системах, до сих пор не всё прикладное программное обеспечение поддерживает корректную работу с ним. В частности, не всегда обрабатываются метки BOM и плохо поддерживаются диакритические символы. Проблема является временной и является следствием относительной новизны стандартов Юникода (в сравнении с однобайтовыми национальными кодировками).
Производительность некоторых программ снижается при использовании Юникода вместо однобайтовых кодировок.
Свойства знаков Unicode
Имя (Name)
В базе данных консорциума Unicode можно встретить два типа записей, где обозначаются имена знаков различных письменностей мира. В Unicode Character Database (UnicodeData.txt) запись имеет пятнадцать текстовых полей и выглядит следующим образом:
041A;CYRILLIC CAPITAL LETTER KA;Lu;0;L;;;;;N;;;;043A;
041B;CYRILLIC CAPITAL LETTER EL;Lu;0;L;;;;;N;;;;043B;
041C;CYRILLIC CAPITAL LETTER EM;Lu;0;L;;;;;N;;;;043C;
041D;CYRILLIC CAPITAL LETTER EN;Lu;0;L;;;;;N;;;;043D;
041E;CYRILLIC CAPITAL LETTER O;Lu;0;L;;;;;N;;;;043E;
Здесь нас интересует только первое и второе поля. Первое — это позиция знака, второе — имя. Причем имя дано достаточно детально. Например, в первой строке мы видим, что, во-первых, это буква, а не цифра или, скажем, знак препинания. Вовторых, эта буква прописная, а не строчная. В-третьих, это буква прописная кириллическая. В-четвертых, это буква [KA], то бишь русская «К». Последнее поле отсылает нас к позиции строчной кириллической буквы «к».
В свою очередь, в документах раздела Unicode Character Code Charts те же самые записи даны следующим образом:
041A К CYRILLIC CAPITAL LETTER KA
041B Л CYRILLIC CAPITAL LETTER EL
041C М CYRILLIC CAPITAL LETTER EM
041D Н CYRILLIC CAPITAL LETTER EN
041E О CYRILLIC CAPITAL LETTER O
Блок и сценарии (Block and script)
По этим свойствам мы можем судить, к какому набору символов и какой системе письменности относятся те или иные знаки. Например (Blocks.txt):
0400..04FF; Cyrillic
0500..052F; Cyrillic Supplement
0530..058F; Armenian
0590..05FF; Hebrew
0600..06FF; Arabic
Здесь понятно, что кириллица находится в диапазоне знаков с 0400 по 04FF, а «арабица» с 0600 по 06FF. Эти сведения часто бывают нужны для разработчиков Unicode-совместимых программных продуктов. Указал нужный диапазон — и можно не волноваться, что пользователь увидит на экране «кракозябры».
Но тут возникает одна проблема… Дело в том, что знаки одной и той же письменности могут располагаться в нескольких блоках. Например, греческий есть в двух блоках, латиница — в пяти, а китайский — аж в четырех блоках в двух разных плоскостях!
Для решения этой проблемы и было придумано такое понятие, как скрипты (Scripts). В настоящий момент существует 66 скриптов: латинский, греческий, кириллица, армянский, иврит, арабский и т.д.
Номер версии (Age)
Позволяет проследить, в какой версии и в каком году был принят тот или иной знак.
Общая категория (General category)
Это, пожалуй, самое важное свойство, которое будет определять поведение знака в тексте (как языковое, так и типографское). Таким образом, у нас набирается 30 двухбуквенных кодов.
Буквы (Letters)
Lu (letter, uppercase) — знак в верхнем регистре. Название категории надо толковать в самом широком смысле — она может применяться в равной степени к букве алфавита, слоговому знаку или идеограмме. Только пять скриптов могут обладать этим свойством — Latin, Greek, Coptic, Cyrillic, Armenian, liturgical Georgian и Deseret.
Ll (letter, lowercase) — знак в нижнем регистре. Эта категория есть зеркальное отражение предыдущей.
Lt (letter, titlecase) — заглавная. Чтобы было понятно, обратите внимание на хорватские диграфы: «Dz», «Lj», «Nj». Так вот, «dz» — это нижний регистр, «DZ» — верхний, а «Dz» квалифицируется как titlecase.
Lm (letter, modifier) — знак-модификатор. Это совсем небольшая категория диакритических знаков, которые не используются самостоятельно, а только со знаком, у которого изменяется звучание при чтении.
Lo (letter, other) — другие знаки. Сюда относится всё, что не вошло в другие категории.
Диакритические знаки (Diacritical marks)
Mn (mark, non-spacing) — это диакритические знаки: акценты, седили и другие, которые являются независимыми Unicode-символами, но в то же время никогда не используются сами по себе. Они тесно связаны с предыдущим знаком, образуя с ним единый символ.
Mc (mark, spacing combining) — как правило, это буквы, которые ведут себя подобно диакритическим знакам, но могут существовать и самостоятельно.
Me (mark, enclosing) — диакритические знаки, имеющие самостоятельное значение.
Числа (Numbers)
Nd (number, decimal digit) — десятичная цифра. Комуто может показаться странным, но в разных частях света люди используют собственные цифры для обозначения чисел от 0 до 9. Мы используем арабские цифры, а арабы — индийские. А еще есть девангари, бенгали, гуарати, телугу, кхмерские и множество других языков с собственным изображением цифр.
Nl (number, letter) — здесь речь идет о буквах, которые могут использоваться в качестве цифр. Ни для кого ведь не секрет, что в старославянском так и было.
No (number, other) — всё, что не вошло в предыдущие категории. Сюда же отнесем цифру «10» из тамильского и амхарского, а также знак «половина» из тибетского.
Пунктуация (Punctuation)
Pc (punctuation, connector) — малочисленная категория знаков пунктуации, которые соединяют две части словоформы. Например, это дефис (желтокрасный, баба-яга, мать-героиня). В японском такую же роль выполняет срединная точка (midpoint) из катаканы, которая используется в основном для трансляции иностранных слов. Еще одним примером соединяющего знака пунктуации может послужить символ подчеркивания «_», который программисты сплошь и рядом используют для написания имен переменных (fko_14_w, aw_rw).
Pd (punctuation, dash) — всевозможные тире: en, em, минус, армянский и монгольский дефисы и т.д.
Ps (punctuation, open) — открывающие знаки препинания: круглые, квадратные, фигурные открывающие скобки и т.п. Заметим, что кавычки сюда не входят. У них есть собственная категория.
Pe (punctuation, close) — закрывающая пара для знаков из предыдущей категории.
Pi (punctuation, initial quote) — бинарные знаки препинания, которые обычно используются в цитировании как открывающие знаки.
Pf (punctuation, final quote) — парные знаки, применяющиеся для обозначения конца цитаты.
Po (punctuation, other) — всё, что не вошло в предыдущие категории. А это такие немаловажные знаки, как точка, запятая, двоеточие, восклицательный знак и др.
Символы (Symbols)
Sm (symbol, math) — эта категория для знаков, которые используются только в математике. Например, в выражении «sin (π) = 0» только знак равенства можно отнести к категории Sm.
Sc (symbol, currency) — знаки валюты: цента (¢), доллара ($), лиры (₤), евро (€), иены (¥) и т.д.
Sk (symbol, modifier) — символы модификации звука и тона. Сюда можно отнести знаки седили, макрона, диереза и т.п.
So (symbol, other) — всеохватывающая категория символов, которые не являются математическими символами, валютными обозначениями и т.д.
Разделители (Separators)
Zs (separator, space) — это пробелы: нулевой ширины, тонкие, средние, широкие, 1-em, 1-en и др.
Zl (separator, line) и Zp (separator, paragraph) — эти категории содержат только по одному знаку: 0x2028 — разделение строк и 0x2029 — разделение абзацев. Фактически это аналог тэгов, известных всем пользователям интернета, — <br> и <p>.
Остальные категории (The remaining categories)
Cc (other, control) — эта категория охватывает позиции 0x0000-0x001F и 0x0080-0x009F, то есть таблицы C0 и C1 в ISO 2022-совместимых кодировках.
Cf (other, format) — эти символы используются для метаданных. Сюда входят такие знаки, как мягкий перенос, маркеры вывода текста справа налево и наоборот (например, для арабских текстов), символы нотной записи и др.
Cs (other, surrogate) — символы высокой и низкой суррогатных зон (0xD800-0xDBFF и 0xDC00-0xDFFF). Используются только в паре. Относятся к 15-му и 16-му планам. Их применение ограничено UTF-16.
Co (other, private use) — символы приватных зон (private use areas).
Cn (other, not assigned) — категория еще не назначенных символов.
Другие общие свойства (Other general properties)
Пробелы (Spaces)
К этой категории относятся 26 символов из категорий Zs, Zl и Zp. Вроде бы то же самое, но вид сбоку.
Буквенные символы (Alphabetic characters)
Данные символы относятся к категориям «Буквы» (Lu, Ll, Lt, Lm и Lo) и «Числа» (Nl). Всего 90 989 знаков.
Беззнаковые (Noncharacters)
Эти кодовые места никто не может использовать, и для нашего экскурса данная категория не имеет значения.
Запрещенные символы (Deprecated characters)
В последней версии Unicode есть девять таких символов, и все они перечислены в PropList.txt.
Логические исключения (Logical-order exceptions)
В основном относится к десятку тайских и лаосских символов, для которых есть правила следования гласных/согласных.
Знаки с плавающей точкой (Soft-dotted letters)
Это символы, которые имеют глифы с точкой («i», «j» и пр.) и при добавлении верхней диакритики теряют эту точку. Например, «i»=> «î».
Математические символы (Mathematical characters)
В данную категорию входят все символы из категории Sm плюс 1069 символов, перечисленных в файле PropList.txt в разделе Other_Math. Это скобки (круг-лые, квадратные, фигурные), оператор «или» и др.
Кавычки (Quotation marks)
Все символы, которые могут быть использованы в качестве кавычек. Категории Po, Pi, Pf, Ps и Pe. Двадцать девять из них перечислены в PropList.txt в разделе Quotation_Mark.
Разделители (Dashes)
Всё, что более или менее похоже на тире и может применяться в таком качестве. Сюда входят 20 символов из категорий Pd (знаки препинания, тире) и Sm (математические символы). Все они перечислены в PropList.txt в разделе Dash.
Дефис (Hyphens)
Данная категория введена, чтобы сделать четкое разделение между дефисом и тире. Речь идет о десяти символах из категорий Pd (знаки препинания, тире), Pc (пунктуация, катакана) и Cf (знаки, потенциальный разрыв строки). Они перечислены в PropList.txt в разделе Hyphen.
Завершающие знаки препинания (Terminal punctuation)
Правильнее было бы сказать, что это знаки препинания, которые ставятся в конце предложения, пункта списка и пр. За неимением лучшего определения можно сказать, что это символы, аналогичные нашим точке, восклицательному и вопросительному знакам, точке с запятой и т.д. Все 78 символов перечислены в PropList.txt в разделе Terminal_Punctuation.
Диакритические знаки (Diacritics)
В данной категории гораздо больше знаков, чем в категории Diacritical marks. В основном за счет специфических знаков азиатских языков. Эти 482 символа перечислены в PropList.txt в разделе Diacritic.
Удлинители (Extenders)
Это символы, роль которых заключается в продлении или повторении предыдущего символа. Особенно часто они встречаются в хирогане и катакане.
Большие буквы (Uppercase letters)
Помимо заглавных букв сюда входят римские цифры. Полный список знаков можно посмотреть в PropList.txt в разделе Other_Uppercase.
Строчные буквы (Lowercase letters)
Здесь трудно чтолибо прокомментировать…
Простой маппинг Title Case/UPPERCASE/lowercase (Simple lowercase/uppercase/titlecase mappings)
Информация для преобразования находится в файле UnicodeData.txt в полях 12 (uppercase), 13 (lowercase) и 14 (titlecase).
Специальный маппинг Title Case/UPPERCASE/lowercase (Special lowercase/uppercase/titlecase mappings)
Восемь наборов символов, создающих проблемы в случае маппинга. Они описаны в файле SpecialCasing.txt, структура которого напоминает UnicodeData.txt.
Выравнивание регистра (Case folding)
Информацию об этом свойстве можно найти в файле CaseFolding.txt, например в виде:
00DB; C; 00FB; # LATIN CAPITAL LETTER U WITH CIRCUMFLEX
00DC; C; 00FC; # LATIN CAPITAL LETTER U WITH DIAERESIS
00DD; C; 00FD; # LATIN CAPITAL LETTER Y WITH ACUTE
00DE; C; 00FE; # LATIN CAPITAL LETTER THORN
00DF; F; 0073 0073; # LATIN SMALL LETTER SHARP S
Обратите внимание: во втором поле могут быть значения «C», «F», «S» и «T»:
- «C» (common case folding) — общее выравнивание;
- «F» (full case folding) — полное выравнивание;
- «S» (simple case folding) — простое выравнивание;
- «T» (Turkic case folding) — тюркское выравнивание (применимо к турецкому и азербайджанскому языкам).
Данное свойство можно описать как процесс, применяемый к последовательности символов, когда те из них, которые идентифицируются как non-uppercase, заменяются своими эквивалентами верхнего регистра.
Как читать записи стандарта Unicode
Каждый знак обозначается тремя способами. Например, 0107 c LATIN SMALL LETTER C WITH ACUTE, где 0107 — код в шестнадцатеричной системе, «c» — принятое обозначение и «LATIN SMALL LETTER C WITH ACUTE» — словесное описание знака.
Описание начинается с буллета «•». Например:
- Polish, Croatian, ...
→ 045B ћ cyrillic small letter tshe
≡ 0063 c 0301
Из чего мы узнаем, что знак относится к польской и хорватской письменностям. В строке, начинающейся со стрелочки (→), указано фонетическое сходство (в данном случае с буквой «ћ»). Строка, начинающаяся со знака ≡, показывает, из каких частей состоит композиция (если знак композиционный).
Если вы увидели знак «≈», то знайте, что он обозначает композиционную сочетаемость — например «'n»≈«’»+«n».
При этом существует 16 тэгов композиционной сочетаемости:
- <font> — подсказка системе, откуда взять знак для вывода;
- <noBreak> — неразрывная версия чего бы то ни было, например неразрывный пробел, неразрывный дефис и т.д.;
- <initial> — инициальная форма знака;
- <medial> — медиальная форма знака в контекстуальном письме;
- <final> — оконечная форма знака в контекстуальном письме;
- <isolated> — изолированная форма знака в контекстуальном письме;
- <circle> — символ внутри круга;
- <super> — верхний индекс;
- <sub> — нижний индекс;
- <vertical> — вертикальная ориентация знака;
- <wide> — полная ширина знака;
- <narrow> — полуширинные знаки катаканы;
- <small> — малые формы;
- <square> — квадратная компоновка;
- <fraction> — дробь;
- <compat> — прочие.
Продолжение следует